Streaming Under Adversity: Building Systems That Survive Reality
Posted on Sat 21 March 2026 | Part 6 of Distributed Systems in Finance | 26 min read
The market just opened and is absorbing the initial burst of orders.
Forty-seven seconds in, the node responsible for aggregating tick data into minute bars crashes. There was no graceful shutdown, no final flush, no checkpoint.
Streaming systems rarely fail at clean boundaries. They fail between operations: after aggregation but before emission, after emission but before offset commit, after snapshot write but before fsync.
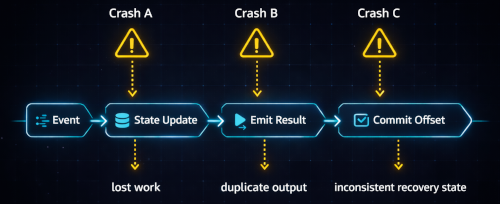
When the node comes back up, the damage may already be done:
- The 47 seconds are replayed and ticks are double counted.
- The system resumes from a stale offset and silently loses data.
- The system emits an incomplete window result due to premature trigger or incorrect watermark advancement.
- A corrupted checkpoint is restored and poisoned state continues forward.
In financial systems, crash recovery is part of the correctness model.
Throughout this article, offset refers to the durable position in an ordered input stream (whether that is a Kafka offset, a sequence number or any other log position).
Core Concepts
Once a streaming computation maintains state across events, crash recovery becomes a coordination problem. The system must keep three things consistent:
- the offset in the stream
- the state derived from processed events
- and the notion of time used to determine when results are complete
If these progress independently, crashes can corrupt results or cause duplication. Streaming systems therefore introduce mechanisms to keep them consistent.
The concepts below define how streaming systems manage this coordination.
Windows and Stateful Computation
Most streaming computations maintain state over bounded slices of the event stream, which are commonly referred to as windows.
A window defines which events contribute to a particular aggregation and when that aggregation is considered complete. For example, a one-minute bar aggregates all trades occurring between 09:30:00 and 09:30:59.999.
Windows can be defined in several ways:
- Time-based windows, such as tumbling or sliding intervals
- Data-driven windows, where completion depends on conditions in the stream (e.g. volume bars or market dynamics regimes)
Regardless of how they are defined, windows require the system to maintain state across multiple events and delay final results until the system believes the window is complete.
This complicates crash recovery. If a failure occurs while a window is still open, replaying input must not produce a different aggregation than the original execution.
Out-of-Order Events and Reordering Buffers
Event streams rarely arrive in strict chronological order. Network latency, retries, partitions and cross-region transport all introduce variability.
For windowed computations, this can change results. Streaming systems therefore introduce reordering buffers which delay processing slightly so earlier timestamps have a chance to arrive.
The buffer size effectively defines how much disorder the system tolerates. Streaming systems choose bounded uncertainty by assuming that events delayed beyond a configured threshold will not appear and release buffered events for processing.
Event Time vs Processing Time
Another source of confusion is the notion of time inside a streaming system. Two clocks are always present:
- Processing time: when the system sees the event
- Event time: when the event actually happened
If computations depend on processing time, results change when events arrive late or when the system replays historical input. Correctness therefore typically relies on event time.
Watermarks
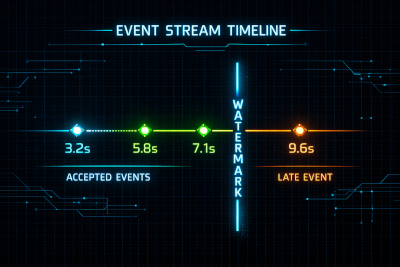
A watermark represents the system's estimate that no earlier event-time data will arrive.
For example, if watermark = 10:01:00, the system assumes all events with timestamps ≤ 10:01:00 have already been observed. Windows ending at or before that time can therefore be finalized.
Watermarks allow systems to advance time without waiting indefinitely for potential late arrivals. The allowed lateness threshold therefore defines a tradeoff between completeness and latency: larger thresholds reduce the risk of missing events but delay results.
In practice, watermark progress can stall if one upstream source stops producing events. Production systems therefore include idleness detection mechanisms that temporarily exclude inactive partitions from watermark computation. Without this safeguard, a single silent source can prevent time from advancing for the entire pipeline.
Partitioning
Streaming systems process large event streams by partitioning the input log. Each partition can be processed independently, allowing the pipeline to scale horizontally.
Ordering guarantees are typically provided only within a partition. Stateful operators therefore maintain state independently for each partition, and replay during recovery occurs per partition.
Partitions rarely progress at the same speed. When operators combine results across partitions, mechanisms such as watermarks, window completion and consistent snapshots must coordinate progress across them. A slow or stalled partition can therefore delay time advancement or checkpoint completion for the entire pipeline.
Checkpoint Barriers
A checkpoint barrier is a marker injected into the event stream. As it flows through the pipeline, each operator records its state when the barrier arrives. Once every operator has done so, the system has a consistent snapshot of the pipeline.
The barrier effectively divides the stream into two regions: events before the barrier are fully reflected in the snapshot, while events after it are not.
Effectively, a checkpoint acts as a commit boundary across state and offset.
Classes of Failure in Stateful Streaming Systems
Once state, time and offset interact, failures rarely manifest as simple crashes. The real problem is that implicit guarantees may no longer hold after restart.
In reality, most correctness failures in stateful streaming systems emerge from a small set of structural patterns:
State & offset coupling failures
If offsets advance without state being durably persisted, data is lost. If state advances without a corresponding offset commit, replay may re-apply already reflected input and cause duplication. State and offset must therefore advance atomically.
Temporal consistency failures
Event-time systems rely on watermarks to decide when a window is complete. If different partitions advance at different speeds, one may signal time progress while others are still lagging. This watermark skew can cause windows to close despite incomplete input.
Clock misalignment across producers can create similar issues. If one producer timestamps events ahead of real time, the system may believe it has progressed further than it actually has, leading to premature window closure or dropped late data.
Idempotency failures
If a windowed aggregation is emitted before its corresponding offset is durably committed, a crash can cause it to be emitted again on replay. Downstream consumers must be designed to handle that duplication.
Snapshot integrity failures
Snapshot writes are not atomic unless explicitly designed to be. A checkpoint written during a crash may be partially persisted. Restoring it continues execution from an inconsistent baseline unless integrity is verified.
Non-deterministic replay
If the same ordered input does not produce the same state after recovery, the system is not recoverable. It is simply restarting.
Determinism, Replay and the Exactly-Once Illusion
The phrase exactly-once processing is frequently used in discussions about streaming systems. Taken literally, it suggests that each event is processed once and only once. However, streaming systems cannot guarantee that an event is processed only once, because recovery almost always involves replaying input. Therefore, replaying must not change the resulting state.
Why Reprocessing Is Inevitable
Return to the crash scenario from earlier. The node fails after aggregating 47 seconds of data into a 1-minute bar, but before committing the input offset. When the node restarts, a subset of the already-processed ticks will be replayed. From the perspective of the log, those events were never acknowledged. Replay is therefore the only correct recovery behavior.
Deterministic Replay
A streaming system is only correct if replay produces the same outputs as live execution.
One effective way to achieve this is to model stream processors as pure functions over ordered logs: stateₙ = f(stateₙ₋₁, eventₙ). If the transition function f is deterministic and the input ordering is preserved, the system can always reconstruct the same state by replaying the log. This also requires that any external reference data (instrument metadata, margin parameters, FX rates) be snapshotted. If replay consults a different external state than the original execution, deterministic replay is impossible even if the transition function itself is pure.

In log-based streaming systems, the event log becomes the canonical source of truth. Derived state is merely a materialized view of that log and can be discarded and rebuilt at any time through replay.
This allows systems to recover from corruption, recompute historical aggregates or rebuild outputs after logic changes without modifying the original input log.
Sources of Non-Determinism
Several common patterns can introduce divergence between live execution and replay:
- Processing-time logic instead of event-time logic
- Random seeds or non-seeded RNG
- Order-sensitive aggregations (e.g. floating-point reductions or iteration over unordered containers)
Each of these can cause replay to produce a different state than the original execution.
Exactly-Once Effects
To preserve deterministic replay, two guarantees are required:
- Idempotent consumers: if replay causes the same input to be processed again, the resulting state transition must not be applied twice.
- Atomic state and offset commits: the offset must reflect exactly the portion of input that is already incorporated into state.
When both guarantees hold, replay becomes harmless. The same ordered input produces the same state regardless of how many times it is processed during recovery.
In reality, a consumer may incur multiple external side effects: updating a database, making a network request, and only then commit the offset. If a crash occurs between steps, the system may only have partially updated its state.
While these operations cannot be made atomic together, the key is to ensure that external effects are idempotent with respect to the input event. Databases enforce this through conflict keys or conditional writes. External APIs expose idempotency keys.
Under this discipline, replay merely attempts to apply the same transition again, which the system recognizes as already incorporated.
Operational Patterns for Replay
Replay appears in multiple parts of a streaming system, but it serves different operational roles.
Online Processing
In the online path, operators consume the live event stream, update state and emit outputs with minimal latency. State is typically held in memory and periodically checkpointed. Replay exists primarily as a recovery mechanism: if a process crashes, it restores its checkpoint and replays the recent portion of the log.
The pipeline operates continuously: live event stream → stateful operators → outputs
In this mode, replay is narrow in scope: the system reprocesses only the portion of the stream necessary to reconstruct its most recent state.
Offline Reprocessing
Offline replay operates on a different scale. Instead of recovering recent state, the system reprocesses large historical ranges.
The pipeline typically runs as a batch job: historical events → batch processing job → rebuilt dataset
In production systems, the streaming log rarely serves as the permanent store of history. Retention is intentionally limited because streaming clusters are optimized for throughput, not indefinite storage.
Raw events are persisted separately in durable storage layers such as databases, analytical warehouses or data lakes. This separation reflects practical constraints: storage economics, cluster stability and the need for efficient analytical access to historical data.
Offline reprocessing rebuilds derived datasets by reading those persisted events and replaying them through the computation pipeline.
Hybrid Architectures
Most production systems combine both approaches.
The online path produces low-latency results by updating state as events arrive. Offline replay allows historical events to be processed again when outputs must be rebuilt.
Designing for Crash Mid-Window
A streaming system must assume that a crash can occur at any point during a window's lifecycle. The design requirement is simple: after recovery, the system must converge to the same final state regardless of when the crash occurred.
Crash During Aggregation
Consider a windowed aggregation that accumulates events in memory until the window closes.
A crash can occur while the window is still being updated. Some events may already have been incorporated into the in-memory state, while others have not yet been processed.
On recovery, the system restores the latest checkpoint and resumes consumption from the corresponding input offset, replaying events until the window state is reconstructed.
A crash may interrupt the aggregation process, but recovery must converge to the same final window result.
Partial Checkpoint Write
If a crash occurs while a checkpoint is being written, the persisted snapshot may be incomplete.
For this reason, checkpoint replacements must be atomic.
A common pattern is to write the snapshot to a temporary file, verify its integrity (e.g. via checksum), and only then promote it using an atomic rename. If the process crashes during the write, the previous checkpoint remains intact and recovery ignores the incomplete file.
In large stateful systems, snapshots are typically incremental rather than full copies, since checkpoint size directly affects recovery time and runtime latency.
Operational Realities of Streaming Systems
Poison Message Handling
A poison message is an input event that cannot be processed by the pipeline. Common causes include deserialization failures, schema drift between producers and consumers, or corrupted data. In these situations the consumer cannot safely interpret the payload.
The pipeline must then decide whether progress should continue. One option is to advance the stream offset while isolating the offending message. This is typically implemented using a dead-letter queue, with metrics and alerts to ensure the failure is visible to operators.
The alternative is to halt the pipeline and require manual intervention.
A critical requirement is that poison message handling must be deterministic under replay. If a message was skipped or quarantined during the original execution, recovery must make the same decision. Otherwise replay can produce a different aggregation result.
Backpressure and Flow Control
Streaming pipelines form a continuous flow of events through multiple processing stages. If one stage processes data more slowly than it receives it, events begin to accumulate. Without flow control, this imbalance propagates upstream. Queues grow, memory pressure increases, and a single slow consumer can eventually stall the entire pipeline.
Streaming systems therefore introduce flow control mechanisms. Common approaches include bounded queues to limit how much data can accumulate between stages, pull-based consumption where downstream operators request data only when they have capacity, producer rate limiting at ingestion boundaries, and horizontal scaling of bottleneck consumers to absorb sustained load.
Partition Skew and Rebalancing
Streaming systems rely on partitioning to distribute work across consumers. Since workloads are rarely uniform, certain keys may generate disproportionately more events, creating hot partitions that process far more data than others.
This leads to uneven resource utilization: some workers remain idle while others become saturated and throughput becomes limited by the slowest partition.
Rebalancing redistributes partitions across consumers to restore balance. However, this often requires migrating operator state between nodes, which can introduce pauses and additional load.
Distributed Joins
Distributed joins combine events from multiple streams based on shared keys. To evaluate the join locally, records with the same join key must be routed to the same partition.
Join operators must coordinate partitioning while maintaining potentially large in-memory state. Join semantics further increase complexity: inner, outer or multi-way joins impose different requirements on completeness, buffering and output timing.
Effectively, joins multiply every difficulty previously discussed.
Why This Matters
Streaming correctness directly affects capital, risk, and decision making. Inconsistencies in the data pipeline propagate into models and trading decisions.
Trading infrastructure is therefore best understood as stream processing with monetary consequences.
For this reason, correctness must take precedence over throughput. A slower system can be scaled. A system that produces incorrect state cannot be trusted, no matter how fast it is.
📚 Distributed Systems in Finance - Part 6
Previous articles
- Part 1: Canton: A Distributed Ledger for Global Finance
- Part 2: Message-Oriented Architectures in Trading Systems: Patterns for Scalability and Fault Tolerance
- Part 3: What Database Scaling Looks Like When Milliseconds Mean Millions
- Part 4: Observability at Scale: Distributed Telemetry for Modern Trading Infrastructure
- Part 5: The Hidden DAG Behind Every Modern Trading System: How Market Data Is Ingested at Scale