What Database Scaling Looks Like When Milliseconds Mean Millions
Posted on Sat 01 November 2025 | Part 3 of Distributed Systems in Finance | 12 min read
In trading systems, latency decides who wins and who gets run over
Scaling Beyond the Web
When most engineers talk about scaling databases, they're thinking about the Netflix problem: millions of users streaming content, horizontal scaling with load balancers, eventual consistency, and maybe some Redis caching on top. That's fine for serving cat videos, but it's the wrong mental model for financial systems.
In quantitative trading and market data infrastructure, the system must instead handle billions of individual data points flowing through every day (instead of having to handle millions of concurrent users). Understanding data locality and optimizing for write throughput during market hours is the correct approach to scaling.
The Three Forces That Break Databases
Before we explore solutions, let's understand what actually kills performance in quantitative systems:
Volume
A single moderately active futures contract generates hundreds of thousands of trades per day. Consider every bid/ask update, every quote change, every order book modification, and we're looking at millions of records per instrument per day multiplied by hundreds of instruments.
Velocity
During the first 30 minutes of trading, high volume is expected, as everyone reacts to overnight news. The write path must handle this without lag or failures, or the downstream systems will be fed corrupted or delayed data.
The problem gets worse when writes and reads happen simultaneously: while the system is ingesting live market data, researchers may query it for backtests or analytics.
Traditional databases with row-level locking start to choke under this kind of pressure.
Volatility
The database needs to handle volatile access patterns. Users might run different queries which can't be optimized with a single index:
- List every trade for AAPL in 2024
- Aggregate minute bars across 50 symbols
- Correlate order flow with price movements
It has to be fast for both narrow & deep (large dataset for a single asset) and wide & shallow (summary stats across assets) access patterns.
Traditional databases struggle to handle both: B-trees are great for point queries but slow on large scans, while columnar storage excels at aggregations but struggles with selective filtering.
Vertical Scaling
Before you start sharding and replicating, consider something simpler: add more RAM and a fast NVMe drive.
RAM Is King
SSDs are fast, but RAM is in a different league: about 100× faster for random access.
If your working set fits in memory (e.g. the last few months of tick data), keep it there. Use memory-mapped files so the OS handles caching. Databases like DuckDB and ArcticDB do this well: they make large datasets feel like they're fully in memory even when they're not.
Efficient CPU Cache Usage
Most engineers optimize for disk I/O and forget about CPU cache entirely. But if the data structures are cache-hostile, a large share of potential performance is lost.
Columnar formats like Parquet exist mostly for this reason: cache efficiency. Storing all prices together and all volumes together lets the CPU prefetch contiguous chunks into L2/L3 cache and process them with minimal cache misses.
When One Machine Is Enough
If the dataset is under a terabyte and most queries are time-based (which is usually the case) a single well-tuned box can go a long way.
kdb+ has proven this for decades: one instance can handle terabytes of history and millions of inserts per second. No distributed complexity and overhead: just efficient memory use and smart partitioning.
Horizontal scaling will come eventually, but it's rarely the first bottleneck. Get everything out of one machine before spreading the problem across many.
Sharding and Partitioning

At some point, even the strongest single machine hits a wall. When that happens, the next step is obvious: split the data. The question is how.
Time-Based Partitioning
Market data is time-ordered, so time-based partitioning is the natural first choice. Each trading day (or month, or year) lives in its own partition, depending on access patterns.
It works because most queries are time-bounded. A query such as "List all trades for AAPL in Q3 2024" hits exactly one partition.
The trade-off shows up at market open: the system writes far more data than it does at the middle of the day. If reads and writes hit the same partition, it turns into a hotspot. One shard is overloaded while the rest do nothing.
Symbol-Based Partitioning
Another option is to shard by instrument.
ES futures go to one shard, NQ to another, AAPL to a third and so on.
This balances the load: writes are spread across all shards instead of hammering one. The downside shows up when you need cross-symbol data. For example, correlation query across 10 stocks means hitting 10 shards and stitching results in application code.
Hybrid Partitioning: Time + Symbol
We can combine both techniques: partition by time first (one directory per day), then within each day, shard by symbol.
This keeps queries time-bounded while distributing writes across multiple shards.
The trade-off is complexity: managing hundreds of partition-shard combinations means that schema changes get harder.
Hot vs Cold: Tiered Storage Architecture
In financial systems, not all data is equal: trades from this morning matter more than trades from three years ago, but most databases treat them the same.
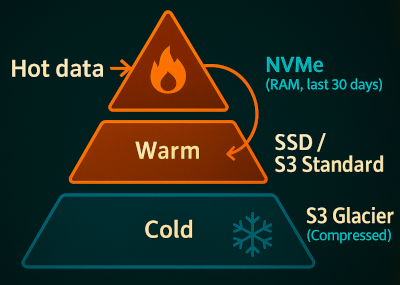
Keep Recent Data Close
The active dataset (e.g. last few weeks of activity) belongs on the fastest storage available: NVMe / RAM. This data is hit constantly: recent backtests, live dashboards, debugging today's signals.
Archive Older Data
Past a few months, data loses urgency. It should be compressed and moved to object storage like S3. Queries will be slower, which is most likely fine: nobody needs sub-second results on 2021 data.
Shifting data from NVMe to cold storage like S3 Glacier cuts cost sharply.
Managing the Transition
The tricky part is managing the data transition from hot to cold storage based as it ages.
Most time-series databases handle this natively: see retention policies in InfluxDB or TTL in ClickHouse.
In simpler setups, a nightly cronjob can do the same: compress partitions older than 30 days, push them to S3, and let the query layer read from both hot and cold tiers transparently.
Real-World Inspiration
A few systems have proven these ideas in production.
ArcticDB: Time-Partitioned Parquet
ArcticDB stores time-series data as Parquet files in S3, partitioned by time. Each partition is a separate file. Queries filter by time range, and metadata indexes let it skip irrelevant partitions. It can scale to petabytes with just efficient organization and compression.
ClickHouse: MergeTree
ClickHouse's MergeTree engine writes data in small chunks, then merges and sorts them in the background.
Old data is compressed more aggressively.
kdb+
kdb+ has followed the same pattern since the 1990s: in-memory tables for recent data, memory-mapped files for history, partitioned by date.
Queries are vectorized and cache-friendly because the language itself is columnar.
The Common Thread
All of them converge on the same design:
- Time-based partitioning: because financial data is always time-series
- Columnar storage: because aggregations are more common than row lookups
- Append-only writes: historical data is immutable
- Tiered storage: recent data fast, older data slower
Conclusion
Scaling databases for financial systems isn't about adopting the latest distributed database or following what works for web companies. It's about understanding your data and your access patterns deeply enough to make intelligent trade-offs.
📚 Distributed Systems in Finance - Part 3
Previous articles
- Part 1: Canton: A Distributed Ledger for Global Finance
- Part 2: Message-Oriented Architectures in Trading Systems: Patterns for Scalability and Fault Tolerance
Next articles
- Part 4: Observability at Scale: Distributed Telemetry for Modern Trading Infrastructure
- Part 5: The Hidden DAG Behind Every Modern Trading System: How Market Data Is Ingested at Scale
- Part 6: Streaming Under Adversity: Building Systems That Survive Reality
- Part 7: Schema Evolution Under Live Order Flow