Schema Evolution Under Live Order Flow
Why Version Skew Turns Schema Changes into a Distributed Systems Problem
Posted on Sun 12 April 2026 | Part 7 of Distributed Systems in Finance | 14 min read
The market does not pause for schema changes. Orders are matched, risk is recalculated, balances are updated, and capital continues to move while the rollout is in progress.
A schema rollout does not transition a system from one version to another. It creates a period where multiple versions coexist and interpret the same data differently.
Because schema changes are events that propagate rather than binary states, the system must remain correct while different components disagree on what the data means.
The Temporal Dimension of Schema Evolution
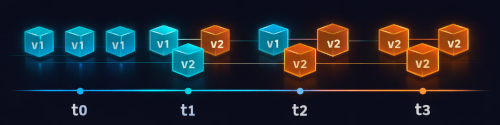
During a rollout, a distributed system does not transition instantly from one version to another. Components upgrade at different times, leaving multiple versions active simultaneously.
Consider a simple evolution of an order event:
OrderEvent v1
{
order_id
price
quantity
}
A new rollout introduces an additional field:
OrderEvent v2
{
order_id
price
quantity
take_profit
}
Once the first upgraded producer begins emitting the new structure, the system may contain a mixture of events:
events written by v1 producers
events written by v2 producers
At the same time, the consumer side may also be mixed:
consumers running v1 code
consumers running v2 code
This coexistence is unavoidable in systems that perform rolling deployments. The same event may therefore be processed by components running different software versions, each interpreting the schema according to its own code. This period of mixed producers and consumers will be referred to here as version skew.
Safe schema evolution requires that the system remain correct while this version skew persists. Compatibility is therefore a mandatory rollout-time requirement.
Structural Failure Modes
Serialization Failures
Some serialization systems fail explicitly on incompatible structure. Others tolerate unknown fields, apply defaults, or partially decode payloads. Structural incompatibility may therefore surface as either a hard failure or silent misinterpretation, depending on the format and decoder behavior.
These failures are most likely during version skew, when producers and consumers do not agree on the active schema.
Structural Changes
More disruptive failures occur when the shape of the data changes.
Example:
{ price, quantity } → { bid, ask, size }
Consumers built against the original structure may no longer be able to interpret the event correctly. Even if deserialization succeeds, downstream logic may rely on fields that no longer exist or whose structure has changed.
Structural changes therefore typically require migration strategies such as expand/contract rather than direct replacement.
In financial systems, schema failures rarely stop at the decoder boundary. They can enter downstream pipelines, derived stores, and reconciliation paths as structurally valid but operationally wrong data. The impact is not limited to message loss. It can include incorrect balances, positions, or exposure computed from payloads that were accepted but misinterpreted.
Patterns for Safe Schema Evolution
Several patterns allow schemas to evolve safely while multiple system versions coexist. These patterns focus on maintaining compatibility during rollout instead of assuming an immediate transition to the new schema.
Additive changes
The lowest-risk structural change is usually an additive one: extending an existing payload without removing or renaming existing fields.
{ order_id, price, quantity }
→
{ order_id, price, quantity, take_profit }
This is safe only if existing consumers tolerate unknown fields and the new field does not alter the meaning of existing ones. For newer consumers, the added field must be optional or explicitly nullable so that historical events remain decodable. A deterministic default may satisfy structural compatibility while still being semantically wrong, so defaults must be chosen with care.
The Expand / Contract Pattern
Structural changes that cannot be expressed as simple additions are typically handled using the Expand / Contract pattern:
- Expand: introduce the new representation alongside the existing one
- Migrate: update consumers to read the new representation
- Contract: remove the legacy representation
The purpose of this pattern is to preserve structural compatibility during rollout by keeping both representations available while consumers migrate. It reduces the need for synchronized upgrade, but it still depends on correct dual-write behavior, equivalent interpretation of both forms, and disciplined removal of the old representation.
Event versioning
Some systems introduce explicit versioned event types. Consumers branch their logic based on the event version. This approach makes evolution explicit and simplifies handling historical replay, since each event version can be interpreted according to the rules that existed when it was produced. The tradeoff is increased code complexity: consumers must maintain logic for multiple versions of the same event.
This approach is common in architectures with long-lived event logs.
Schema Registry & Compatibility Enforcement
Many production systems enforce schema compatibility using a schema registry. Registries validate new schemas against previous versions using rules such as:
- Backward compatibility: new consumers can process old data
- Forward compatibility: old consumers can process new data
- Full compatibility: both directions hold
However, registries validate structural compatibility, not semantic changes.
Translation Layers
Systems with long-lived logs often introduce translation layers.
Rather than forcing every consumer to understand every historical schema version, the system defines a canonical internal representation. When older events are read, they are translated into this representation before being processed.
Translation layers are common in systems that rely on replay, such as event-sourced architectures and financial systems that rebuild state from historical logs. This comes at the cost of additional complexity and potential overhead on hot paths.
Operational Playbooks for Safe Rollouts
Evolving schemas under live order flow requires concrete, repeatable rollout procedures.
- Producer-last rollout: consumers should be upgraded first and must accept both old and new schema forms.
- Canary consumers: deploying a small set of upgraded consumers on production traffic can expose anomalies early before full rollout. It may miss failures tied to rare event types, tenant-specific patterns, or edge cases absent from the sample.
- Per-version monitoring: message volume, deserialization failure rate, validation error rate, and processing latency should be tracked per schema version.
- Automated compatibility gating should be integrated in the rollout pipeline as a blocking step. Every schema modification must pass backward (or forward) compatibility validation against the currently registered schema before promotion to production.
- Shadow writes / dual emission: for high-risk changes, producers emit both old and new representations under a feature flag. The new schema is validated in production before consumers begin using it. In high-throughput systems, this also increases bandwidth, storage, and validation cost during rollout.
These procedures reduce the chance that incompatibilities survive into full rollout. They do not eliminate semantic error, but they move detection earlier, when rollback and containment are still practical.
Replay Extends the Compatibility Burden
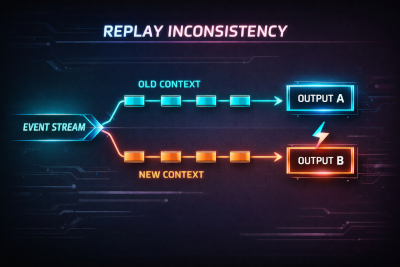
Events in an immutable log are stored with their original schema. Replay must process each event according to the schema version under which it was written.
Consumers must therefore handle all retained schema versions present in the log.
Schema evolution in a replay-capable system is cumulative. Compatibility is not only a rollout-time requirement but a historical obligation.
Structural versioning alone is not always sufficient. Replay may also depend on interpretation context such as reference data or computation rules that evolve independently of the schema. A system that can process live traffic but cannot correctly replay historical data has not preserved correctness.
Structural Compatibility Is Not Semantic Safety
Semantic evolution occurs when the meaning of a field changes while its name and type remain unchanged. These changes are not detected by structural validation and cause consumers to produce incorrect results despite successfully parsing well-formed messages.
Example: a price field is initially defined as mid-price (average of best bid and best ask). The upstream system later switches the field to last trade price. The schema remains identical, but downstream consumers continue interpreting the value as mid-price. Models, reports, and decisions now operate on incorrect assumptions while producing outputs that appear valid.
The defect arises from a divergence between the producer's semantics and the consumer's assumptions. Unlike structural incompatibility, this failure mode is silent and propagates through the system.
Schema evolution in a live system creates a period of version skew in which old and new payloads, producers, and consumers coexist. Structural safety during that window depends on compatibility discipline: additive change where possible, staged migration where necessary, and rollout controls that surface decoder and validation failures before full promotion.
Replay extends that burden further. Historical payload versions remain part of the contract long after the live rollout ends. A system that can process current traffic but cannot correctly decode or translate retained history has not solved schema evolution.
📚 Distributed Systems in Finance - Part 7
Previous articles
- Part 1: Canton: A Distributed Ledger for Global Finance
- Part 2: Message-Oriented Architectures in Trading Systems: Patterns for Scalability and Fault Tolerance
- Part 3: What Database Scaling Looks Like When Milliseconds Mean Millions
- Part 4: Observability at Scale: Distributed Telemetry for Modern Trading Infrastructure
- Part 5: The Hidden DAG Behind Every Modern Trading System: How Market Data Is Ingested at Scale
- Part 6: Streaming Under Adversity: Building Systems That Survive Reality