The Hidden DAG Behind Every Modern Trading System: How Market Data Is Ingested at Scale
Posted on Sat 24 January 2026 | Part 5 of Distributed Systems in Finance | 17 min read
Why linear pipelines break at scale

Everyone begins with the same comforting picture: market data as a neat, linear pipe. Data in, logic in the middle, trades out. It feels obvious and orderly. And then the first real market event hits (CPI, a surprise rate move, a sudden halt) and that mental model collapses.
Nothing about market data is linear: it arrives from different regions, at different rates, over different protocols, each with its own quirks and ordering semantics. And it has to be consumed simultaneously by subsystems with incompatible requirements: low latency for strategies, determinism for risk, completeness for surveillance, durability for storage.
Linear ingestion collapses the moment multi-rate feeds, mixed workloads, backpressure, replay, ML feature extraction, or parallel consumers start pulling in different directions. It becomes one long chain of coupled failure domains.
Trading systems stay fast, correct, and resilient because they branch, isolate, transform, and replay. A directed acyclic graph is the only structure that survives the actual physics of live markets.
What a DAG is
A directed acyclic graph is simply how market data moves once multiple consumers, rates, and guarantees enter the system. At its simplest, a DAG is just this:
- Nodes perform transformations
- Edges carry data between them
- Acyclic means data only moves forward
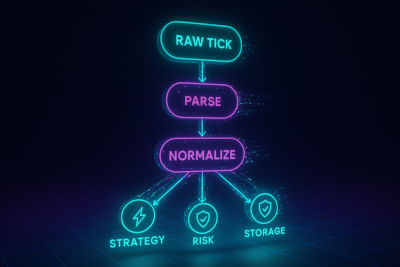
A node might parse raw ticks, another normalizes symbols, another enriches events with extra data. Downstream nodes consume those transformed events independently, each according to its own latency, durability, and correctness requirements.
The key difference from a linear pipeline is decoupling. Data is transformed once, then branched. Consumers advance independently, with their own guarantees and failure modes.
Fan-Out
Market data is consumed by multiple systems at once, with incompatible requirements. Forcing those consumers through a single linear path pushes the strictest requirement onto everyone. Latency explodes or correctness erodes.
DAGs branch early, localize backpressure, and keep fast paths fast. That's what keeps a CPI print from taking down the entire trading stack.
Fan-In Is Where Structure Pays Off
Fan-in nodes are where parallel streams are combined into a single coherent view.
Ordering, sequencing, deduplication, and reconciliation live at explicit fan-in nodes, not scattered across downstream consumers.
Because the graph makes these merge points explicit, global guarantees are established in one place. Everything downstream can rely on them. That's what makes replay and new downstream consumers possible without reworking ingestion from the ground up.
Why This Solves the Failures from Linear Pipelines
Linear pipelines fail because they tie transformation, routing, and consumption into a single coupled path. When load spikes, that coupling turns local stress into system-wide failure.
DAGs separate those concerns:
- Bursts are absorbed by individual branches instead of propagating
- Failures stay localized instead of cascading
- Replay is localized to the nodes that need it
- New consumers attach without destabilizing the core
Market data is inherently concurrent, multi-rate, and adversarial. DAGs simply match that reality.
Market Data Ingestion in Trading Systems
Ingestion starts with raw feeds coming in from different protocols, transports, and vendors. Each one behaves differently, delivers different fields, and fails differently.
Raw market data sources
Trading systems typically pull from several feed types at once, each with its own characteristics:
- Exchange-native feeds such as ITCH and OUCH. Fast, dense, and low-level.
- FIX feeds: slower but more structured.
- Vendor feeds: aggregated and normalized upstream. Slightly delayed due to vendor processing.
- Multicast transports: broadcast-style delivery used by many exchanges. Fast, but lossy. Packet drops, bursts, and NIC pressure are normal operating conditions.
These feeds arrive at different rates, from different regions, with different failure modes. The first job of the ingestion DAG is to contain this chaos and turn it into something stable enough for the rest of the stack.
Early-stage transforms
Before any strategy logic exists, ingestion is already doing work that must be deterministic, and correct:
- Decoding: parse raw bytes into structured events.
- Normalization: unify symbols, venues, scales, and event types into one internal model.
- Cleaning/validation: detect gaps, duplicates, resets, malformed messages, and stabilize the stream so downstream nodes don't get poisoned.
- Timestamp harmonization: decide which timebase drives the system (exchange, receive, hardware, monotonic) and make it consistent.
This stage happens once, then fans out. Downstream systems should never redo it.
Fan-out to subsystems
Once normalized, events branch into consumers with different requirements:
- Strategies: need the fastest possible view of events.
- Risk: needs a consistent, ordered stream it can replay and verify.
- Order book reconstruction: needs every sequence update in order to maintain book state.
- Surveillance/compliance: needs complete data even if it arrives late.
- Audit/PnL/post-trade: needs a reliable record of every event exactly as it was seen live.
- Analytics/research: consumes the stored output of ingestion later, without adding load to the live DAG.
Each branch runs independently without affecting each other.
The Lifecycle of a Record Through the DAG
When a tick enters the system, it moves through a defined path in the DAG: shedding ambiguity, gaining structure, and branching into the parallel views the trading stack relies on.
Clean entry → Enrich → Branch → Roll Up → Merge → Feed ML → Feed Control-Plane
- Clean entry: by the time a record gets here, it's already decoded, normalized, and sanity-checked.
- Enrich: attach metadata and lightweight derived fields: instrument config, venue info, tick size, or small precomputed hints that help downstream consumers avoid redundant work.
-
Branch: This is where the DAG splits according to requirements:
- Low-latency branch: minimal, allocation-light stream for strategy engines.
- Deterministic branch: ordered, replayable, correctness-first; used by risk state machines.
- Completeness branch: tolerant of lag but intolerant of gaps; used by surveillance and compliance.
- Durable branch: append-only and storage-focused; used for audit, PnL, and historical analytics.
-
Roll Up: some consumers need structure over time: rolling volume, imbalance metrics, volatility windows, and similar aggregates.
- Merge: multi-region, multi-protocol, or multi-venue streams get reconciled into a single coherent stream. Global ordering, deduplication, and reconciliation live here.
- Feed ML: feature extractors transform enriched events into higher-level signals.
- Feed Control-Plane: each record also emits metrics like latency, sequencing drift, regional skew, or burst signatures. The control-plane uses them to spot divergence early and flag when ingestion drifts from baseline.
The lifecycle looks linear on paper. In reality, it behaves like a lens: one event enters, and the DAG expands it into the guarantees a trading system needs to stay fast, correct and resilient under stress.
Stateful Branches: Rollups, Aggregates, and Windowing
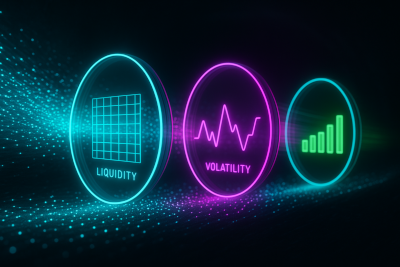
Some branches of the DAG care about behavior over time rather than individual data points. They hold state, update it on every tick, and emit rolling views across short horizons.
Rolling spreads smooth out micro-bursts. Rolling volatility captures how unstable the tape has been over the last few seconds. Windowed liquidity shows how quickly size is refilling. Rolling PnL gives a fast read on regime fit. Together, these converge toward a stable picture that raw ticks can't provide on their own.
Stateful branches turn noisy microstructure into something that can actually be reasoned about.
Failure Modes Unique to Ingestion DAGs
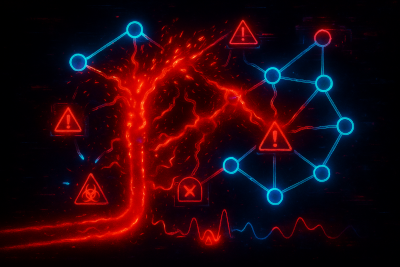
DAGs solve the coupling problems of linear pipelines, but they introduce their own failure modes:
- Backpressure and merge pressure: when a branch falls behind and its queue fills, the slowdown pushes backward unless flow is isolated. Merge nodes also choke when branches produce outputs at very different rates.
- Hot nodes: a single node doing too much work becomes the bottleneck for the entire graph.
- Resource imbalance: different branches stress different resources (CPU, storage, memory). Without resource isolation, heavy branches slow down everything else.
- Latency skew: branches process the same event at different speeds and downstream consumers end up with misaligned views.
- Out-of-order issues: events arrive out of order for many reasons. Poor reordering logic leads to duplicates, drops, or broken windows.
- Partial branch failure: one branch dies or stalls, and without proper fault isolation its failure leaks into healthy branches.
- Replay drift: replayed data doesn't match live output due to nondeterministic ordering or hidden state.
A robust ingestion DAG expects these failure modes and contains them by design.
Real-World Constraints
Some practical constraints also shape how ingestion DAGs run in production:
Zero-copy paths: ultra-low-latency systems avoid data copies entirely. High-fan-out DAGs use shared-memory rings or kernel-bypass to let branches read the same bytes without duplication.
FPGA pre-processing: decoding and filtering happen on hardware before the CPU sees a packet.
Clock discipline: ordering only works if servers agree on time. Distributed deployments rely on PTP to keep clocks aligned, and small drift between machines can reorder events that were correct at the source.
Cloud vs. Colocation: multicast works well in colocation environments but is rarely available in the cloud.
These constraints define the environment in which the DAG runs.
Design Principles for Building Robust Ingestion DAGs
These are the fundamentals that keep ingestion predictable under load and easy to reason about. By following them, the system behaves the same on calm days and on days where everything is on fire.
- Branch isolation: backpressure and retries never spill into other parts of the graph.
- Crash-safe nodes: a node must resume from storage or checkpoints without corrupting downstream state.
- Safe error boundaries: failures should be contained inside the node where they occur. They don't cascade across branches.
- Deterministic ordering: a single ordering rule must be applied consistently in branches that require ordering. Nodes that depend on order should produce the same state whenever they see the same ordered inputs.
- Windowed state: any time-based metric should live inside an explicit window with a defined size and eviction policy.
- Versioned schemas: schemas should carry versions so nodes can handle migrations without breaking.
- Idempotency: the same input should always produce the same output. No surprises.
- Lineage-awareness: every derived value should be traceable back to the raw events that produced it. Debugging and forensics become trivial.
- Replayability: the DAG should be able to rebuild any derived value from stored observations. Needed for validation, baselines, new products, and recovery.
These principles make ingestion durable, explainable, and stable under real conditions.
📚 Distributed Systems in Finance - Part 5
Previous articles
- Part 1: Canton: A Distributed Ledger for Global Finance
- Part 2: Message-Oriented Architectures in Trading Systems: Patterns for Scalability and Fault Tolerance
- Part 3: What Database Scaling Looks Like When Milliseconds Mean Millions
- Part 4: Observability at Scale: Distributed Telemetry for Modern Trading Infrastructure