Ring Buffers 101: The Building Block of Low-Latency Systems
Posted on Sat 04 October 2025 | Part 4 of Low-Latency Fundamentals | 12 min read
It's 3:47 AM. Your trading system is processing 50,000 market data updates per second when suddenly... latency spikes to 200 microseconds. Orders start getting rejected. Your P&L bleeds red.
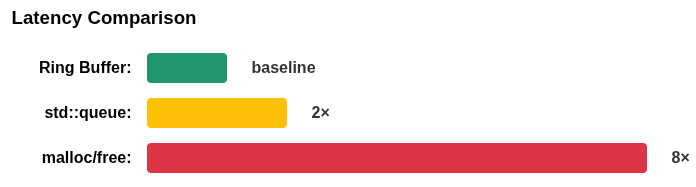
Later, you discover the culprit: your message queue was doing malloc() for every packet. The fix? A 1KB ring buffer (also called circular buffers or lock-free queue) that never allocates memory.
This is why ring buffers matter.
What is a Ring Buffer?
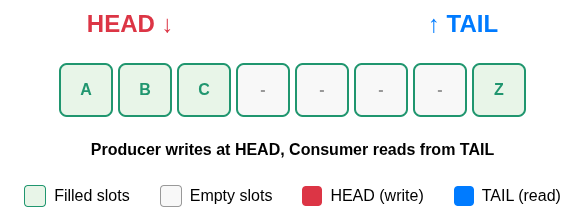
A ring buffer is a fixed-size array used as a queue where the end "wraps around" to the beginning.
Two pointers (or indices) track its state:
- Head: the position where the producer writes the next element.
- Tail: the position where the consumer reads the next element.
When either index reaches the end of the array, it loops back to 0, like a clock hand going past 12 (hence the name ring)
Ring Buffer In Action
Below is a simple interactive demo.
Click Enqueue Data to add elements, and Dequeue Data to consume them.
Watch how the head (write pointer) and tail (read pointer) move around the circle, wrapping back to the beginning when they reach the end.
This is exactly how real ring buffers behave in kernels, feed handlers, and audio drivers.
What Happens if Head Runs Faster?
If the producer writes faster than the consumer reads, eventually:
- Full buffer: head catches up to tail.
- What happens next depends on policy:
- Reject new data (common in trading, networking, real-time systems where dropping is safer than corrupting).
- Overwrite old data (common in logging, telemetry, audio where newest is most important).
If the consumer runs faster than the producer, the buffer simply goes empty (head == tail), and reads fail until more data arrives.
Why are Ring Buffers Fast?
- Lock-free (single producer / single consumer): with one writer and one reader, no locks needed.
- Cache-friendly: data is contiguous in memory, reducing cache misses.
- Predictable latency: no dynamic allocations, no fragmentation, no "surprise" pauses.
- Zero system calls: everything happens in userspace.
Implementation Optimizations
Power-of-2 Size Trick
Here's a crucial optimization most implementations use:
#define SIZE 1024 // Must be power of 2!
int buffer[SIZE];
int head = 0, tail = 0;
bool enqueue(int x) {
int next = (head + 1) & (SIZE - 1); // Fast modulo!
// int next = (head + 1) % SIZE; // Slower variant
if (next == tail) return false; // full
buffer[head] = x;
head = next;
return true;
}
bool dequeue(int *x) {
if (head == tail) return false; // empty
*x = buffer[tail];
tail = (tail + 1) & (SIZE - 1); // Fast modulo!
// tail = (tail + 1) % SIZE; // Slower variant
return true;
}
Why this works: (head + 1) & (SIZE - 1) is equivalent to (head + 1) % SIZE when SIZE is a power of 2, but uses a cheap bitwise AND instead of expensive division.
Memory Barriers (Advanced)
In multi-threaded environments, you need proper memory ordering:
// Producer
buffer[head] = x;
__atomic_store_n(&head, next, __ATOMIC_RELEASE);
// Consumer
int local_head = __atomic_load_n(&head, __ATOMIC_ACQUIRE);
if (local_head != tail) {
*x = buffer[tail];
tail = (tail + 1) & (SIZE - 1);
}
This ensures the data write completes before the head pointer update becomes visible.
When do you need memory barriers? In single-threaded applications or when using a single ring buffer within one thread, you can skip the atomic operations entirely. But the moment you have one thread writing and another reading, you need these memory barriers. Without them, the CPU might reorder operations: the consumer could see the updated head pointer before the actual data write completes, leading to reading garbage. The __ATOMIC_RELEASE/__ATOMIC_ACQUIRE pair ensures the data write happens-before the pointer update becomes visible to other threads.
Variants of Ring Buffers
Ring buffers are simple, but the variations are where things get interesting:
- SPSC (Single Producer, Single Consumer): The simplest and fastest variant, often completely lock-free. Perfect for feed handlers where one thread receives network packets and another decodes them.
- MPSC (Multi-Producer, Single Consumer): Multiple threads can write, but only one reads. Common in logging systems where trading strategies, risk engines, and market data threads all write to a single log processor thread.
- SPMC (Single Producer, Multi-Consumer): One writer, multiple readers. Used in pub-sub scenarios like broadcasting market data updates to multiple strategy engines.
- MPMC (Multi-Producer, Multi-Consumer): The most complex variant, often avoided unless absolutely necessary. The coordination overhead can make it slower than a simple mutex-protected queue.
Rule of thumb: Start with SPSC when possible. Each additional producer or consumer adds coordination complexity that can hurt performance more than it helps.
Common Use Cases in Finance
- Market Data Feed Handlers: Network packets get dropped into a ring buffer for decoding.
- Order Gateways: Outbound messages are queued in a ring to the NIC or kernel.
- Loggers: Trading events are written to a ring, flushed by a background thread.
- Kernel drivers: NICs and sound cards expose rings between hardware and kernel.
- Audio Trading Alerts: Buffers smooth over timing mismatches between producer and consumer.
References
Conclusion
Ring buffers may look almost trivial, but their simplicity is the very reason they show up in so many high-performance systems. Understanding them gives you the foundation to appreciate why operating systems, network drivers, and trading platforms all lean on the same fundamental pattern.
They're the building block that makes sub-microsecond latencies possible in modern trading systems.