Scaling Trading Systems Beyond Pandas
Posted on Sun 03 May 2026 | Part 5 of Building Real Trading Systems | 19 min read
At small scale, trading data is loaded into memory, features are computed, and backtests run on top of derived datasets. The entire pipeline executes within a single process, often within a single DataFrame.
This model couples computation to data loading: each run requires reloading the dataset and recomputing derived features. Serialization and caching can be introduced to avoid repeated work across runs, but the cost shifts toward I/O and data movement.
As the dataset grows, this model breaks: startup time increases, memory usage rises and iteration speed slows down.
Data Layout as Part of the Backtesting Contract
Once trading data no longer fits in a single DataFrame, storage stops being a passive implementation detail. Physical and logical layout determine which operations are cheap: time-range scans, symbol filters, feature computation, and repeated backtests over historical windows. This makes data layout part of the contract between storage and the backtesting engine.
The conventional workflow is simple: load the dataset, compute features, execute the strategy. Storage appears once, as a blocking I/O step before computation starts.
At larger scale, that model becomes too expensive. The execution model shifts toward ingesting raw events once into a layout optimized for downstream access patterns. Derived representations are then generated on demand or maintained incrementally through materialized views and pre-aggregations.
For stable and reusable transformations, the goal is to move computation closer to storage. Trading data, fills, quotes, and other event streams remain durable, while symbol-specific ranges, historical windows, and derived datasets can be retrieved with minimal I/O and recomputation.
A backtesting engine built on this model spends less time preparing data and more time evaluating strategies.
The Middle Ground Before Analytical Storage
ClickHouse is not the first step after Pandas. Many systems can scale a long way with partitioned Parquet, DuckDB, Polars, Arrow, or memory-mapped datasets. Those tools are often the right middle ground when the workload is still single-user, batch-oriented, or research-local. The case for an analytical database becomes stronger when the same raw data and derived datasets are reused across many runs, symbols, users, time windows, or services.
Why Backtesting and Research Workloads Favor Scan-Oriented Storage
Research and backtesting workloads are often dominated by time-range scans and large aggregations. Execution systems, order management, and live risk checks have different access patterns and should not be modeled the same way.
Typical backtesting queries are:
- trades for a symbol between
t0andt1 - VWAP over a session
- volume distribution across price levels
These queries scan over large portions of the dataset and touch only a subset of fields.
Row-oriented storage groups fields into complete records. This supports point access and updates efficiently, but large scans pay the cost of reading full rows even when most columns are irrelevant to the query.
Columnar storage reorganizes data by field. Each column is stored independently, allowing scans to read only the required data. Aggregations operate over contiguous values of the same type, and compression reduces the amount of data read from disk.
Access patterns drive the shift from lookup-oriented storage to scan-oriented storage as datasets grow and analytical queries dominate.
MergeTree: Immutable Parts and Background Merges
MergeTree stores data as immutable, sorted parts.
Each insert produces a new part. A part is a self-contained batch of rows written to disk, organized column-wise and sorted by the primary key, typically (symbol, timestamp). Existing data remains unchanged and history is extended through new parts.
Columnar layout isolates values by field. Within each column, values follow predictable patterns: symbols repeat across large ranges, timestamps increase monotonically, sizes have low cardinality. These patterns enable compression through run-length, delta, and dictionary encodings.
Parts accumulate as data is ingested. Background merges combine smaller parts into larger ones, preserving sort order and improving compression. Over time, the layout converges toward fewer parts.
Parts are also grouped into partitions, usually derived from time. Partitions define lifecycle boundaries such as retention and deletion.
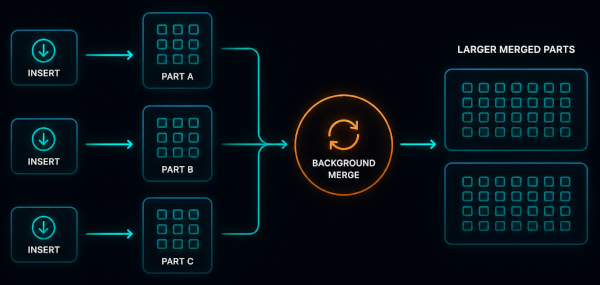
Queries do not scan every row in every part. Execution narrows the search space in stages. Partitions eliminate entire time ranges before data is read. Within remaining partitions, rows are physically sorted by the primary key, allowing scans to focus on relevant ranges.
Each part is further divided into granules, typically thousands of rows at a time. A sparse index stores metadata for each granule rather than each individual row, allowing large ranges to be skipped without maintaining expensive row-level indexes.
Because columns are stored and compressed independently, queries can read only the fields they need. This keeps disk I/O much lower than the raw dataset size would suggest.
MergeTree encodes a model based on append-only writes, sorted storage, and background convergence. These constraints align well with the dominant shape of trading data: mostly append-heavy, mostly time-ordered streams.
Ingestion as a Systems-Engineering Concern
In a Pandas-based pipeline, ingestion is local and implicit. Data is loaded into a DataFrame and processed within a single process.
With ClickHouse, ingestion becomes part of the storage design. Write patterns affect part creation, background merges, compression, and query performance over time.
This introduces explicit engineering decisions:
- Batching: group rows into fewer, larger
INSERToperations to reduce part creation. - Buffering: accumulate records in memory or an intermediate store and flush by interval, size, or watermark.
- Write fan-in: consolidate multiple producers into a controlled number of insert streams.
- Retry behavior: prevent data loss without creating uncontrolled duplicates.
- Idempotency: define deduplication rules so repeated ingestion can converge to the same dataset.
Ingestion design becomes part of the storage architecture: the way data is batched, retried, deduplicated, and flushed directly affects storage layout, merge pressure, and query performance.
Continuous Computation With Materialized Views
Pandas workflows frequently recompute identical derived datasets. As data volume and iteration rate increase, full recomputation imposes increasing compute and latency costs.
A storage-backed model provides an alternative: materialized views that compute derived tables incrementally. When new data is inserted, the system transforms the inserted block and writes the result into a target table, rather than regenerating the full derived dataset.
This pattern maps directly to standard trading system transformations:
- Ticks → 1-minute bars: OHLCV bars aggregated from tick events
- Executions → session VWAP: cumulative volume and notional maintained from execution records
- Trades → volume profile: traded volume grouped by price level
- Fills → realized PnL: realized totals derived from fill records
- Order book updates → depth metrics: spread, top-of-book size, imbalance, or liquidity by price level computed from book updates
In each case, materialized views shift computational cost from query time to ingestion time. That tradeoff only pays off when the derived dataset is reused often enough to justify the additional ingest complexity.
The raw table should remain the source of truth. Derived tables are cached interpretations of that truth.
Handling Imperfect Data
Trading feeds are not perfectly ordered. Duplicate ticks, delayed events, corrections, backfills, and out-of-order messages can introduce multiple versions of the same dataset over time. The storage model must define how overlapping records resolve into a dataset the backtester can trust.
Superseded Records: ReplacingMergeTree
ReplacingMergeTree fits records that can be superseded: corrected trade prints, updated quote snapshots, and revised vendor records. Multiple rows may exist for the same logical record. During background merges, the engine collapses rows with the same sorting key, retaining the row with the highest version when a version column is configured.
Deduplication is eventual. Queries may observe multiple versions until merges complete, so query logic must account for intermediate states when exact results are required.
State Transitions: VersionedCollapsingMergeTree
VersionedCollapsingMergeTree fits data modeled as state transitions rather than overwrites. Order lifecycle events, position adjustments, and cancel/replace flows follow this shape: rows represent changes, and opposing states are collapsed using sign and version semantics.
After merges, matching positive and negative rows cancel each other out. The resulting table represents the surviving state without requiring in-place updates.
Failure Modes Shift With the Architecture
Moving beyond Pandas removes one class of bottlenecks and introduces another. Bottlenecks move toward ingestion behavior, storage layout degradation, and correctness of incremental computation.
High-frequency tick ingestion can degrade storage performance when write patterns produce excessive numbers of small parts. Background merges must continuously compact these parts into larger sorted parts. If ingestion outpaces merge capacity, part fragmentation increases, metadata overhead grows, and query latency deteriorates.
Derived datasets introduce a second failure mode: temporal inconsistency. Trading data is not strictly append-only. Duplicate ticks, delayed prints, exchange corrections, and historical backfills can arrive after downstream bars, VWAP series, or volume profiles have already been materialized. Once computation shifts from query time to ingestion time, the system must define how corrections propagate through previously derived datasets.
Storage growth introduces a third constraint. Raw tick datasets expand continuously, while most research workflows repeatedly access only recent windows. Retaining all historical data in high-performance analytical storage eventually turns fast retrieval into an unnecessary cost center. Mature systems separate hot analytical storage from colder archival layers and restore older datasets only when required.
Scaling beyond Pandas redistributes preprocessing costs across storage systems, ingestion pipelines, and lifecycle management.
Where ClickHouse Fits in a Trading Architecture
ClickHouse is not a substitute for all databases or runtime components in a trading stack. Its role is limited to research, backtesting, and post-trade analysis workloads, where large volumes of historical and derived trading data must be queried with high scan and aggregation efficiency:
- Historical tick storage: ingesting and querying billions of raw ticks across instruments and time ranges.
- Backtesting datasets: serving as the source for cleaned, normalized trading data consumed by backtesting engines.
- Derived bars: storing precomputed OHLCV bars, VWAP series, and other aggregations at multiple time resolutions.
- Execution analytics: analyzing fill quality, slippage distributions, and venue-level execution statistics post-trade.
- Strategy performance analysis: computing returns, drawdowns, Sharpe ratios, and other metrics across strategy variants and time periods.
- Market microstructure research: exploratory queries over order book snapshots, trade-and-quote data, and spread dynamics.
It is not suitable for execution-critical functions such as order routing, live risk checks, mutable account state management, or low-latency execution paths.
A trading architecture should make this separation explicit: in-memory systems should handle execution and risk-sensitive logic, event logs should support replay and streaming workflows, and ClickHouse should store analytical history and derived datasets built from those event streams and operational records.
A Concrete Example: From Raw Ticks to Backtest-Ready Data
A simple setup starts with a raw tick table ordered by (symbol, timestamp). Incoming ticks are batched into inserts, stored durably, and partitioned by date.
A materialized view aggregates ticks into 1-minute OHLCV bars. Another table stores derived features such as VWAP, volume-at-price, or rolling volatility. Backtests no longer load the full raw dataset on every run. They query the required symbol, session, and feature set.
The backtesting engine becomes a consumer of prepared historical windows rather than a system that rebuilds every dataset from scratch.
Small trading systems gain measurable throughput from code-level optimization. Pandas remains effective for strategy prototyping, exploratory dataset analysis, and initial pipeline construction. Its constraints show up when system requirements exceed the single-process, in-memory DataFrame execution model.
As system scope increases, bottlenecks migrate from code paths to architectural boundaries. Larger trading systems optimize the data system itself: layout, movement, lifecycle management, and incremental derived computation.
📚 Building Real Trading Systems - Part 5
Previous articles
- Part 1: Setting up an Ubuntu 24.04 EC2 instance for algorithmic trading with Interactive Brokers
- Part 2: Interdependence of returns across multiple strategies
- Part 3: How to Build Execution Systems for Crypto Trading at Scale
- Part 4: Designing Fault-Tolerant Async Trading Services in Python
Next articles
- Part 6: Trading Systems Are Data Systems