How to Build Execution Systems for Crypto Trading at Scale
Posted on Sun 12 October 2025 | Part 3 of Building Real Trading Systems | 35 min read
I've spent the last few years building trading systems that run across multiple venues and products. Over time, I realized that execution infrastructure is the main product every other components should be built around.
This post outlines the core principles and design patterns I've found most effective when building execution systems that scale across spot and derivatives markets.
Market Data Ingestion
Trading systems can't execute well without solid market data: Garbage In → Garbage Out.
The Multi-Venue Reality
Crypto markets are naturally fragmented. Liquidity is scattered across centralized and decentralized venues, each with its own protocol and quirks.
- Binance: Streams incremental order book deltas. You maintain a local book, applying updates by sequence.
- Coinbase: Sends full L2 snapshots on every update: simpler, but at much higher bandwidth cost.
- Bybit: Uses inconsistent timestamp formats and field names across REST and WebSocket APIs.
- Others: Differ in sequencing rules, heartbeat mechanisms, and throttling limits.
Every integration is slightly different, which is why robust normalization layers and per-venue adapters are essential.
Symbol Normalization
Venues may potentially have different symbol conventions. A standard way to handle this is to normalize symbols using a mapping:
SYMBOL_MAP = {
'venueA': {
'BTC/USD': 'BTCUSD',
'ETH/USD': 'ETHUSD',
},
'venueB': {
'BTC.USDT': 'BTCUSD',
'ETH.USDT': 'ETHUSD',
}
}
def normalize_symbol(venue, symbol):
canonical = SYMBOL_MAP[venue].get(symbol)
if not canonical:
raise ValueError(f"Unknown symbol {symbol} for {venue}")
return canonical
WebSocket Disconnections
WebSocket feeds are the lifeblood of any trading system, but we cannot assume that they will always be stable (spoiler alert: they won't).
Disconnections are normal and must be handled gracefully and not treated as rare events.
As software engineers, we must always prepare for the worst case scenarios and design our systems accordingly. So, a production-grade feed handler must:
- Detect drops immediately: monitor for missing heartbeats or stalled sequence numbers.
- Reconnect automatically: with exponential backoff and rate-limit awareness.
- Resynchronize the book: fetch a REST snapshot, then replay deltas from the last known sequence.
- Log everything: reason codes, uptime durations, and reconnect latencies help diagnose systemic issues.
We don't aim for perfect connectivity, but for fast, deterministic recovery.
Execution Architecture
Order Lifecycle Management
Orders go through different states during their lifetime:
from enum import StrEnum
class OrderState(StrEnum):
PENDING = "pending"
SUBMITTED = "submitted"
PARTIALLY_FILLED = "partially_filled"
FILLED = "filled"
CANCELLING = "cancelling"
CANCELLED = "cancelled"
REJECTED = "rejected"
class Order:
@property
def is_cancellable(self):
return self.state in [OrderState.SUBMITTED, OrderState.PARTIALLY_FILLED]
@property
def is_terminal(self):
return self.state in [OrderState.FILLED, OrderState.CANCELLED, OrderState.REJECTED]
The system should store every state transition in an append-only log. When the system restarts, it can replay the log to reconstruct state.
Venue Adapter Pattern
As previously mentioned, each exchange has its own API quirks (different authentication schemes, parameter names, rate limits, error codes, etc...)
Without abstraction, we would end up with venue-specific logic scattered throughout the codebase, making it brittle and hard to maintain. As John F. Woods once said: "Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live". I couldn't agree more.
The adapter pattern prevents such a mess by encapsulating all venue-specific behavior behind a unified interface. The order manager talks to adapters, not to exchanges directly.
class VenueAdapter(ABC):
@abstractmethod
async def place_order(self, order: Order) -> str:
pass
@abstractmethod
async def cancel_order(self, venue_order_id: str) -> bool:
pass
class BinanceAdapter(VenueAdapter):
async def place_order(self, order: Order):
# Handle Binance-specific order params
params = {
'symbol': exchange_symbol('binance', order.symbol),
'side': order.side.upper(),
'type': 'LIMIT',
'quantity': self._format_quantity(order.quantity),
'price': self._format_price(order.price),
'timeInForce': 'GTC'
}
# Generate signature
params['signature'] = self._sign_request(params)
response = await self.client.post('/api/v3/order', params)
return response['orderId']
This pattern keeps venue integration isolated and testable. When it's time to add a new venue, we simply implement the adapter interface.
Order Routing and Execution
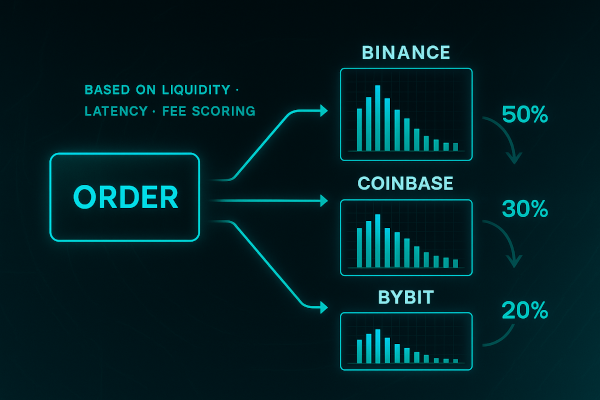
Order routing determines where and how your orders execute.
Smart Order Routing
Smart order routing scores venues across multiple dimensions:
-
Liquidity depth: Walk the order book to calculate the effective price for your order size. A venue with slightly worse top-of-book but deeper liquidity often delivers better execution.
-
Queue depth: Estimate the resting volume ahead of your passive order at the intended price level. Large queues reduce the likelihood of timely fills.
-
Fee structure: Factor in maker/taker fees. Some venues offer negative maker fees (rebates). Others have tiered fee schedules based on volume. The "best" price pre-fees might be worse post-fees.
-
Historical performance: Track recent fill quality per venue. If a venue consistently delivers worse execution than its quoted prices suggest, downweight it in routing decisions.
-
Latency: Prioritize venues that acknowledge orders faster, with low and stable latency (especially p95/p99), not just fast p50s. Low jitter means more predictable fills, which is critical during fast-moving markets.
-
Backpressure penalty: Monitor each venue's responsiveness in real time (pending order counts, rising latency, or stale market data are signs of strain). Apply a dynamic penalty score to overloaded venues to proactively redirect flow and avoid cascading failures.
In practice, these signals can be combined into a weighted scoring model balancing cost, reliability, and execution probability. During stable conditions, fees and book depth dominate. But during high volatility, queue depth, latency jitter, and backpressure penalties often outweigh nominal price advantage. A smart router adapts to both.
def select_venue(self, symbol, side, quantity):
venues = self.get_active_venues(symbol)
scores = {}
for venue in venues:
book = self.market_data.get_book(venue, symbol)
# Calculate effective price including depth
levels = book['asks'] if side == 'BUY' else book['bids']
effective_price, available_qty = self._walk_book(levels, quantity)
if available_qty < quantity * 0.8: # Need at least 80% available
continue
# Factor in fees
fee_rate = self.get_fee_rate(venue)
price_with_fee = effective_price * (1 + fee_rate if side == 'BUY' else 1 - fee_rate)
# Factor in recent fill quality
venue_score = self.metrics.get_venue_score(venue)
scores[venue] = {
'price': price_with_fee,
'venue_score': venue_score,
'combined': price_with_fee * (1 + venue_score * 0.01)
}
best_venue = min(scores.items(), key=lambda x: x[1]['combined'])[0]
return best_venue
This approach picks the venue most likely to deliver good execution for this specific order.
Adaptive Execution
Markets are complex adaptive systems.
Volatility, liquidity, and order book dynamics shift constantly: execution must adapt to the current conditions.
Additionally, the execution system should implement anti-gaming logic to dodge predatory algos.
Retry and Idempotency
Network failures are common. Imagine the following scenario: you send an order, the network times out, you don't know if it was placed. If you retry blindly, you might get a double fill. If you don't retry, you might miss the trade entirely.
This is essentially the double-spend problem in distributed systems: how do you ensure an action happens exactly once when you can't rely on perfect communication? The network might drop your request, delay it, or deliver it twice.
Solution: Generate client order IDs before sending. Most exchanges support client-assigned IDs that make retries idempotent: just like how blockchain transactions use nonces to prevent double-spending.
Track retry counts and escalate after N attempts. If an order can't place after N retries, something's systematically wrong and needs human intervention.
Execution Quality and Monitoring
Once the system can route and execute orders reliably, the next challenge is to measure how well it performs because what isn't measured can't be improved.
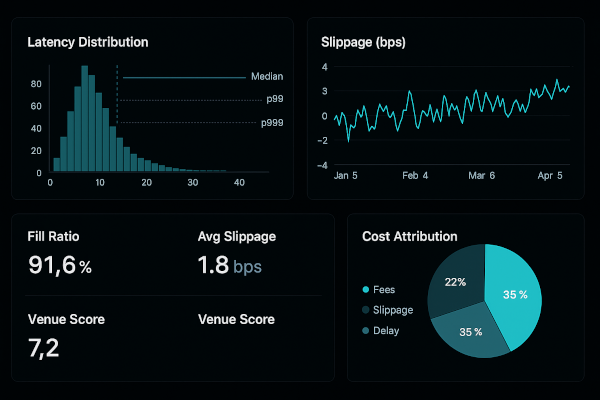
Core metrics
Execution quality is multidimensional. Raw speed matters, but it's only one piece of the puzzle.
-
Fill ratio is the percentage of intended notional that actually executed. If you tried to buy $1M but only filled $800K, that's an 80% fill ratio. Low fill ratios indicate either insufficient liquidity or overly aggressive pricing. Track this per venue and order type.
-
Slippage measures the difference between your decision price and actual fill price. If you decided to buy at $120,000 but filled at $120,020, that's 4 basis points of slippage. Some slippage is inevitable but consistent slippage in one direction suggests systematic issues.
-
Latency distribution tells you about system consistency. Median latency (p50) shows typical performance, but p99 and p999 reveal tail behavior: the times when something goes wrong. In production, tail latencies often matter more than averages. A system with 10ms median but 500ms p99 has a problem.
class ExecutionMetrics:
def __init__(self):
self.fills = []
def record_fill(self, order, fill, decision_price):
slippage_bps = (fill.price - decision_price) / decision_price * 10000
self.fills.append({
'timestamp': fill.timestamp,
'symbol': order.symbol,
'venue': order.venue,
'side': order.side,
'quantity': fill.quantity,
'fill_price': fill.price,
'decision_price': decision_price,
'slippage_bps': slippage_bps,
'latency_ms': fill.timestamp - order.created_at
})
def get_daily_report(self):
df = pd.DataFrame(self.fills)
report = {
'total_volume': df['quantity'].sum(),
'avg_slippage_bps': df['slippage_bps'].mean(),
'median_latency_ms': df['latency_ms'].median(),
'fill_ratio': self._calculate_fill_ratio(),
'by_venue': df.groupby('venue').agg({
'slippage_bps': 'mean',
'latency_ms': 'median'
})
}
return report
Venue Performance Scoring
Not all venues perform equally, and their relative quality changes over time based on market conditions, liquidity shifts, and technical issues.
The system should track historical fill quality per venue. Every fill should stored along with its context: decision price, execution price, time of day, market volatility. It will be useful to build venue performance profiles and uncover key insights: which venues consistently deliver better execution during high volatility, which ones have better depth for large orders, etc...
Adverse selection happens when you consistently buy at local highs and sell at local lows. If your fills systematically occur at worse prices than the mid-market shortly after, you're getting adversely selected. This often means your signals are leaking information or your execution is too predictable.
To detect adverse selection, compare your fill price against the market price 30 seconds and 5 minutes after execution. If the market consistently moves against you immediately after filling, you're signaling your intent too clearly or hitting stale quotes.
These metrics should be used to build dynamic venue rankings: the Smart Order Routing algorithm should factor in recent fill quality, adverse selection rates, and latency variance.
Post-Trade Analytics
Post-trade analysis reveals patterns that aren't visible in real-time. Daily execution reports should break down performance by venue, time of day, and market conditions.
Compare decision price (when the signal fired) against execution price (what you actually paid). This delta tells you whether your routing logic works or whether you're getting adversely selected. If the delta consistently grows during volatile periods, your execution isn't adapting to market conditions.
Track cost attribution separately: how much came from exchange fees versus slippage versus execution delay. This breakdown shows you where to optimize next. If fees dominate, negotiate better rates or route differently. If slippage dominates, you need to improve execution logic or trade smaller sizes. If delay dominates, you have a latency problem.
Look for patterns by time of day. Some venues have better liquidity during Asian hours. Others perform better during US market hours. Use these patterns to inform routing decisions dynamically.
Resilience and Fault Tolerance

Failures are part of normal operation. A resilient system detects, isolates, and recovers from bad data or venues without affecting the rest of the flow.
Circuit Breakers
When a venue starts failing, continuing to hammer it with requests wastes API quota, delays order execution, and creates alert fatigue. Circuit breakers automatically stop traffic to failing components until they recover.
class CircuitBreaker:
def __init__(self, error_threshold=5, timeout=60):
self.error_count = 0
self.error_threshold = error_threshold
self.timeout = timeout
self.last_error_time = None
self.state = 'CLOSED'
def call(self, func, *args, **kwargs):
if self.state == 'OPEN':
if time.time() - self.last_error_time > self.timeout:
self.state = 'HALF_OPEN'
else:
raise CircuitBreakerOpen("Too many failures")
try:
result = func(*args, **kwargs)
if self.state == 'HALF_OPEN':
self.state = 'CLOSED'
self.error_count = 0
return result
except Exception as e:
self.error_count += 1
self.last_error_time = time.time()
if self.error_count >= self.error_threshold:
self.state = 'OPEN'
raise
Wrap venue calls in circuit breakers. After five consecutive failures, the breaker opens and rejects requests immediately for 60 seconds. After the timeout, it enters a half-open state: one successful call closes it fully, one failure reopens it.
This prevents cascading failures. When one venue goes down, the circuit breaker isolates it quickly while your routing logic redirects orders to healthy venues.
Operational Resilience
Connection Management
As previously stated, WebSocket connections aren't guaranteed to be stable. Therefore, the system must handle failures gracefully.
-
Detecting failures: Monitor for missing heartbeats, stalled sequence numbers, and error rates above thresholds. Detect problems proactively.
-
Reconnection strategy: Use exponential backoff with jitter. Immediate reconnection after a drop often fails because the issue hasn't resolved. Backoff gives the venue time to recover while jitter prevents thundering herd problems when multiple connections retry simultaneously.
-
Throttling: Track API rate limits per venue. Many exchanges count limits per API key, not per connection. If you exceed limits, you get banned temporarily. Build a request queue that respects limits automatically.
-
Timeouts: Set aggressive timeouts on API calls. A request stuck for 30 seconds is worse than a failed request because it ties up resources. Fail fast, retry, and move on.
State Recovery
When your order manager crashes, you can't assume a clean slate. Orders might be open on venues even though your local state is gone. The recovery process:
- Replay the event log: Your append-only log contains every state transition. Reconstruct your internal order state by replaying these events from the last known good checkpoint.
- Query venues for open orders: Your view might be stale. Each venue adapter should query for all open orders and return them.
- Reconcile: Compare your log against venue reality. If an order exists on the venue but not in your log, something was missed. If an order is in your log but not on the venue, it was filled or cancelled.
- Resume operation: Only after full reconciliation should you start accepting new orders. Inconsistent state leads to double-fills or missed positions.
async def recover_state(self):
# Step 1: Replay event log
self.order_manager.replay_events(self.event_log)
# Step 2: Query all venues
venue_orders = {}
for venue in self.venues:
venue_orders[venue] = await venue.get_open_orders()
# Step 3: Reconcile
discrepancies = self.reconcile(
self.order_manager.orders,
venue_orders
)
if discrepancies:
self.alert(f"Found {len(discrepancies)} discrepancies during recovery")
self.log_discrepancies(discrepancies)
# Step 4: Resume
self.order_manager.set_state('RUNNING')
Health Monitoring
You can't fix what you don't measure. Track system health continuously and alert on anomalies before they become incidents.
Critical metrics:
- Order placement latency: Time from order creation to venue acknowledgment. Rising latency indicates network issues or venue degradation.
- Fill rate: Percentage of orders that fill within expected timeframe. Dropping fill rates suggest liquidity problems or pricing issues.
- Book freshness: Time since last order book update per venue. Stale books mean feed problems.
- Reconnection count: Number of WebSocket reconnects per hour. Spikes indicate venue instability.
- Error rates by venue: Track errors per venue adapter. Systematic errors mean API changes or venue issues.
Alerting thresholds: Don't trigger an alert for every minor fluctuation. Focus on rate of change: for example, if latency suddenly spikes, alert. If it's creeping up slowly, just log it. Too many false alarms and people stop paying attention.
Dashboards: Build real-time dashboards showing order flow, venue health, and execution quality. When something breaks at 3 AM, you need to diagnose it in seconds, not minutes.
In production trading systems, downtime or degraded performance directly translates to lost opportunity or worse, losses. Catching issues early is the difference between a recoverable incident and a costly failure.
Conclusion
The systems described in this post are the basis for any institutional-grade crypto trading operation (or any asset class really)
Bad execution compounds: a few basis points of slippage or a few seconds of delay can turn into material losses. Building for scale means assuming things will fail and engineering for graceful recovery.
The following must be taken into consideration:
-
Handling every edge case in market data
-
Comprehensive state tracking and reconciliation
-
Rigorous risk management before orders hit exchanges
-
Continuous measurement and optimization of execution quality
-
Resilience patterns that expect things to break
In the end, great execution systems are about consistency, resilience, and trust. Build those well, and everything else follows.
📚 Building Real Trading Systems - Part 3
Previous articles
- Part 1: Setting up an Ubuntu 24.04 EC2 instance for algorithmic trading with Interactive Brokers
- Part 2: Interdependence of returns across multiple strategies