Go's Runtime Model for High-Throughput Services
Posted on Sat 16 May 2026 | 30 min read
Modern infrastructure services spend a large portion of their time waiting: on sockets, queues, databases, locks, timers, disk I/O, and downstream systems.
Go is built around that reality. Goroutines make in-flight work cheap to represent, while the runtime scheduler decides how that work is executed on a smaller set of operating system threads.
This is the model behind many Go services: large amounts of waiting work, a smaller amount of active execution, and a runtime responsible for keeping the process moving.
The Go concurrency model
While Go's concurrency primitives appear simple, they rely on a runtime that manages their execution.
Concurrency vs Parallelism
Concurrency means a system can make progress on multiple tasks during the same period of time. The tasks may be interleaved, paused, resumed, or waiting on I/O.
Parallelism means multiple tasks are literally running at the same instant, usually on different CPU cores.
So concurrency is about structure and coordination. Parallelism is about simultaneous execution.
Goroutines
Go exposes concurrency through goroutines. Programs create many lightweight execution units, while the runtime decides how these units are executed.
The runtime multiplexes many goroutines onto a smaller pool of operating system threads. These threads are then scheduled onto CPU cores by the operating system.
Goroutines begin with very small stacks (roughly ~2 KB). When additional space is required, the runtime allocates a larger stack and copies the existing stack frames to the new location, updating pointers as needed. Because stack management happens entirely in user space, the runtime can grow stacks on demand instead of reserving large fixed stacks like OS threads, allowing Go programs to run millions of concurrent goroutines.
Once a program can create large numbers of goroutines, the next problem is execution: deciding which waiting tasks should run on a limited number of CPU cores.
The Go Scheduler
While goroutines define units of concurrent work, their execution is orchestrated by the Go runtime scheduler. It is responsible for deciding which goroutines run, when they run, and on which threads they execute.
Instead of relying entirely on the operating system scheduler, Go introduces a runtime layer that multiplexes large numbers of goroutines onto a smaller set of threads.
In high-throughput systems, scheduler latency (the delay between a goroutine becoming runnable and actually executing) can influence tail latency under extreme load.
The G-M-P Model
The Go scheduler is built around three core concepts:
- Goroutine: a unit of concurrent work
- Machine: an OS thread
- Processor: a runtime context required to execute Go code
The scheduler is responsible for binding runnable goroutines (G) to processor contexts (P), which are then executed by operating system threads (M).
GOMAXPROCS controls the number of P instances, which caps how many goroutines can execute Go code simultaneously.
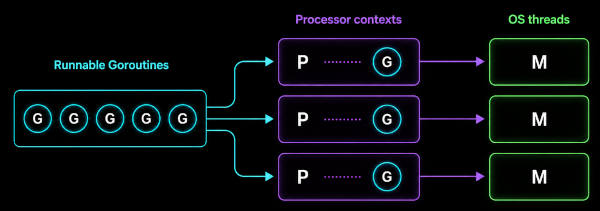
Multiplexing Goroutines
Even though a Go program may create thousands of goroutines, only a small subset of them execute at any moment. The scheduler maintains queues of runnable goroutines waiting to execute. When a processor (P) becomes available, the scheduler selects one of these goroutines and runs it on the associated thread (M).
Goroutines yield control back to the scheduler when they block on I/O, perform channel operations, wait on synchronization primitives, or reach preemption points inserted by the runtime. When this happens, the runtime suspends the current goroutine and schedules another runnable one. This allows a small number of threads to make progress on a very large number of goroutines.
Context Switching
Switching between goroutines happens entirely inside the Go runtime.
Unlike OS thread scheduling, which requires kernel involvement, goroutine switches occur in user space. The runtime saves the execution state of the current goroutine and restores the state of the next one.
Because this switch does not require a kernel transition, it is significantly cheaper than an operating system context switch.
Run Queues and Work Stealing
Each processor (P) maintains its own local run queue of goroutines ready to execute. Early versions of Go relied primarily on a global run queue, which became a scalability bottleneck under high concurrency.
When a goroutine becomes runnable (e.g. after I/O completes or a synchronization primitive is released), it is typically placed on the run queue of the processor that scheduled it. Keeping work local reduces contention on shared scheduler state and improves CPU cache locality.
If a processor exhausts its local queue, the scheduler attempts to steal work from another processor. A portion of the runnable goroutines from the busy processor is transferred to the idle one, allowing the idle processor to continue executing goroutines.
Work stealing allows large numbers of goroutines to be executed efficiently across multiple cores, making it well suited for high-throughput systems where thousands of tasks may become runnable concurrently.
The trade-off is that stealing introduces overhead and can reduce cache locality, since goroutines may migrate between processors.
Blocking and Scheduling
Goroutines frequently perform operations that cannot complete immediately, such as network I/O, system calls, or synchronization on shared data structures. When this happens, the goroutine cannot make progress and must yield execution.
The Go runtime then parks the goroutine by removing it from the run queues and placing it in a waiting state until the blocking condition is resolved. Once the blocking condition is resolved, the goroutine becomes runnable again and is placed back onto a run queue.
Blocking system calls require special handling. If a goroutine enters a syscall that blocks the underlying thread, the runtime detaches the processor from that thread and may create another thread to continue executing runnable goroutines. This prevents blocking system calls from halting scheduler progress.
By parking blocked goroutines and scheduling runnable ones, the Go runtime ensures that blocking operations do not halt overall progress, even in highly concurrent programs.
Scheduler Fairness and Starvation
In highly concurrent programs, the scheduler must ensure that runnable goroutines eventually receive execution time. Otherwise, some goroutines could remain runnable but never actually execute, a condition known as starvation.
Starvation can occur when long-running goroutines monopolize a processor without yielding. If left unchecked, this can delay the execution of other runnable goroutines.
Early versions of Go relied primarily on cooperative scheduling: where goroutines voluntarily yield execution. While effective in many cases, purely cooperative scheduling could allow CPU-bound goroutines to run for extended periods, starving other runnable goroutines.
Modern Go versions introduced asynchronous preemption to address this problem. The runtime keeps track of how long a goroutine runs on a processor and requests preemption once it exceeds an internal threshold (roughly ~10ms). The goroutine then yields at the next safe point, allowing the scheduler to run another runnable goroutine.
Together, cooperative yielding and runtime preemption help maintain fairness across large numbers of goroutines.
Garbage Collection
Go's garbage collector is designed to minimize pause times in highly concurrent programs. It uses a tri-color mark-and-sweep algorithm combined with concurrent marking, allowing most of the collection work to occur while the application continues executing.
The tri-color algorithm classifies objects into three sets during marking:
- white: objects that have not yet been discovered
- gray: objects that have been discovered but whose references have not yet been scanned
- black: objects that have been fully scanned
Go performs most of this marking concurrently with running goroutines, allowing application execution to continue during the majority of the GC cycle.
However, concurrent marking introduces a subtle problem: while the garbage collector is tracing object references, running goroutines may continue modifying pointers in the heap. To preserve correctness, Go uses write barriers. When a goroutine writes a pointer to the heap, the runtime intercepts the write and records the reference, allowing the garbage collector to observe newly created references.
On top of this, the runtime still requires brief stop-the-world phases at specific points in the GC cycle. During these pauses, all goroutines are temporarily suspended so the runtime can safely transition between phases of the GC cycle.
Stack vs Heap
Objects with short lifetimes limited to a function scope are typically allocated on the stack. Stack allocation is extremely fast and memory is reclaimed automatically when the function returns, without involving the garbage collector.
Objects whose memory must outlive the current stack frame are allocated on the heap and managed by the garbage collector. Heap allocations are more expensive because they must be tracked and eventually reclaimed by the GC.
Object Lifetime
Object lifetime is another factor that determines GC cost.
Objects that remain reachable for longer periods must be traced repeatedly during the marking phase. As the number of long-lived objects increases, the collector must scan a larger portion of the heap during each GC cycle.
Problems arise when objects remain reachable longer than intended. They increase the size of the live heap and the amount of memory the collector must scan during marking. As the live heap grows, each GC cycle requires more work.
Allocation Behavior
When large numbers of objects are allocated on the heap, the allocation rate increases and the heap grows quickly. This growth triggers more frequent GC cycles. At high allocation rates, the garbage collector must run more frequently to reclaim memory.
Reducing unnecessary heap allocations or reusing objects (e.g. via sync.Pool) can therefore lower GC pressure and improve overall performance.
Network I/O
Network I/O is a central workload for many Go programs. To avoid blocking entire threads while waiting for network operations, the Go runtime integrates its scheduler with the operating system's non-blocking I/O mechanisms.
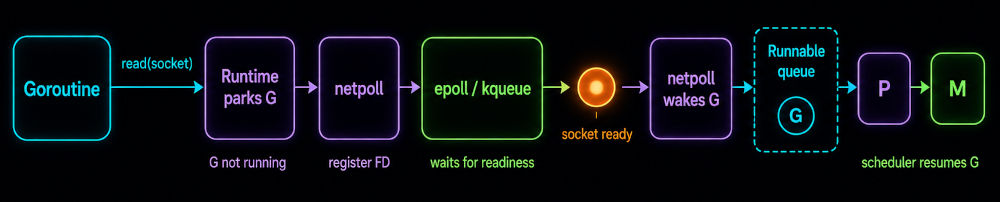
When a goroutine performs a network operation, the runtime configures the underlying socket in non-blocking mode and registers its file descriptor with an internal network poller (netpoll). If the operation cannot complete immediately, the runtime parks the goroutine and removes it from the scheduler's run queues. The underlying thread can then continue executing other runnable goroutines instead of blocking.
The network poller waits for readiness events from the operating system. When an event arrives indicating that a socket is ready for reading or writing, the poller marks the associated goroutine as runnable and places it back onto a scheduler run queue. The scheduler can then resume execution of the goroutine on an available processor.
This integration between the scheduler and the runtime network poller allows Go services to efficiently manage large numbers of concurrent network operations without dedicating a thread to each connection.
Scheduling many goroutines is only half the problem. A service also needs to coordinate shared state, transfer ownership, and establish memory visibility between concurrent tasks.
Coordination Primitives
Concurrency allows many goroutines to execute simultaneously, but shared resources must still be coordinated. Without proper coordination, concurrent execution can lead to race conditions, inconsistent state, or memory visibility issues.
Channels
Channels are commonly used to coordinate goroutines and transfer ownership of data between concurrent tasks. By passing values instead of sharing mutable state, many Go systems reduce the amount of explicit locking required.
Channels can operate synchronously or as bounded queues. Buffered channels are often used to implement producer–consumer pipelines or to absorb short bursts of work.
Mutexes
When multiple goroutines access shared data structures, services rely on mutual exclusion to prevent race conditions.
The sync.Mutex type provides a simple locking mechanism that ensures only one goroutine can access a protected region of code at a time. However, excessive locking can lead to lock contention, where many goroutines compete for the same lock.
The sync.RWMutex type allows multiple readers to access shared data concurrently while still ensuring exclusive access for writers. This can improve throughput when reads greatly outnumber writes.
In high-throughput systems, contention can be reduced with lock sharding. Instead of protecting an entire structure with a single lock, the structure is partitioned into smaller segments, each guarded by its own lock.
Atomics
While mutexes protect critical sections, atomic operations provide low-overhead synchronization for simple shared state such as counters and flags.
Atomic operations are implemented using hardware instructions, allowing updates to occur without acquiring a mutex. Because they avoid blocking and scheduler overhead, atomic operations typically incur far less synchronization overhead than mutexes.
Go Memory Model
Concurrency introduces another challenge beyond mutual exclusion: memory visibility. When goroutines run on different CPU cores, writes performed by one goroutine may not immediately be visible to others.
The Go memory model defines the rules that determine when a write in one goroutine becomes visible to another.
Its central concept is the happens-before relationship: if an operation happens before another, all memory writes performed by the first are guaranteed to be visible to the second.
Synchronization primitives such as mutexes, channels, and atomic operations establish these happens-before relationships, ensuring that concurrent programs observe a consistent view of memory.
The runtime provides the primitives, but production systems combine them into recurring execution patterns.
High-Throughput Service Patterns
Worker Pools
Worker pools are commonly used to bound parallelism in services that process large volumes of tasks. Units of work are placed into a shared queue and consumed concurrently by multiple workers. Each unit is processed by exactly one worker. This pattern allows a service to control parallelism while keeping the number of active goroutines bounded.
Fan-Out / Fan-In
Fan-out / fan-in patterns distribute work across multiple workers and then aggregate results into a single stream.
→ worker
input → → worker → results
→ worker
Work may be divided into independent subtasks processed in parallel, or replicated across multiple workers.
Fan-out increases throughput by exploiting parallelism, while fan-in restores a single stream of results for downstream processing.
💡 Real high-throughput services are usually compositions of worker pools and fan-out / fan-in patterns.
Pipelines
Many Go systems are structured as pipelines, where data flows through a series of processing stages.
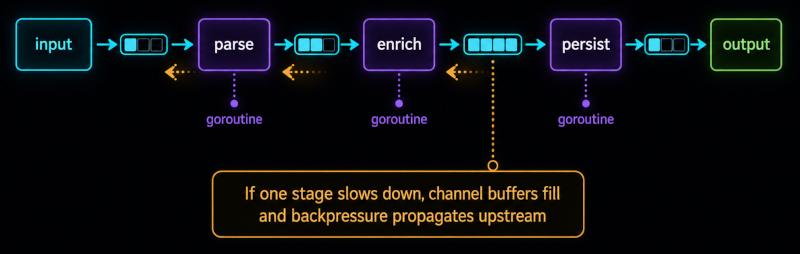
Each stage transforms the data and passes results to the next stage through a channel. Pipelines allow the decomposition of complex workflows into smaller concurrent components.
This introduces an important operational constraint: backpressure propagation. If one stage slows down, upstream stages eventually block as channel buffers fill.
Systems must therefore define what happens under overload. The appropriate flow control strategy depends on the service's latency and reliability requirements.
Context Propagation
Production services must also coordinate lifecycle control. Go's context package provides a standard mechanism for propagating cancellation signals, deadlines, and request-scoped values across goroutines.
Context propagation ensures that cancellation signals and deadlines propagate through the call graph, allowing abandoned work to terminate promptly.
Graceful Shutdown
Real services must handle termination safely. An abrupt shutdown can interrupt in-flight work, corrupt state, or drop partially processed requests. Graceful shutdown involves propagating cancellation signals, stopping new work, and draining in-flight tasks before terminating workers.
Channels are often closed to signal that no more work will arrive. Workers exit once the channel is closed and drained. This pattern allows services to restart without losing work or leaving the system in an inconsistent state.
Contention and Failure Modes
Concurrency primitives also introduce new classes of failure. Under load or incorrect coordination, goroutines can block indefinitely, resources may accumulate, and the runtime can become overwhelmed.
- Deadlocks: multiple goroutines waiting on each other indefinitely, preventing them from making any progress.
- Blocked Channels: channel operations can block indefinitely if the corresponding send or receive never occurs.
- Runaway Fan-Out: unbounded fan-out can spawn large numbers of goroutines and exhaust system resources.
- Race Conditions: occur when multiple goroutines access shared state without proper synchronization, causing non-deterministic behavior.
These failures often manifest operationally as goroutine leaks: goroutines that remain alive but can no longer make progress. Over time, leaked goroutines accumulate, increasing memory usage and scheduling overhead until the system eventually degrades or fails.
Operating Go Services in Production
Error Handling
In concurrent services, error handling also defines cancellation behavior. A failed downstream call may need to cancel sibling goroutines, drain work queues, or stop a pipeline before more work accumulates. Patterns such as errgroup, contexts, and explicit error channels help keep failure propagation controlled.
Panics and Recovery
Panics are different from ordinary errors. A panic inside a goroutine can bring down the entire process if it is not recovered.
recover only works from a deferred function in the same goroutine that is panicking. It is a local safety boundary, not a replacement for normal error handling.
Observability
Concurrent systems are difficult to reason about without instrumentation. Structured logging, metrics, and tracing provide the signals needed to understand system behavior in production and observe system health and performance.
Profiling and Debugging
When production systems degrade, runtime diagnostics become critical. Go exposes several profiling and debugging tools through its runtime and the net/http/pprof package, allowing inspection of running services:
pprofprofiles for CPU, memory, and blocking analysisruntime metricsfor observing internal runtime behaviorexecution tracesfor analyzing scheduling and goroutine activitygoroutine dumpsfor identifying blocked or leaked goroutines
The runtime also exposes metrics such as goroutine counts, scheduler latency, and GC statistics that allow better understanding of system behavior under load.
Race Detection
Concurrent programs are particularly susceptible to race conditions. Go provides a built-in race detector that can identify unsynchronized memory access during testing: go test -race.
Go's runtime is a major reason the language fits infrastructure services dominated by I/O, coordination and background work.
Goroutines represent concurrent work cheaply. The scheduler multiplexes that work onto operating system threads. The network poller resumes goroutines when sockets become ready. Synchronization primitives define how shared state is coordinated. The garbage collector shapes latency and memory behavior under load.
Production issues often surface at these boundaries: blocked goroutines, scheduler delay, allocation pressure, lock contention, backpressure, goroutine leaks, and unbounded fan-out.
Understanding the runtime makes these failures easier to diagnose.